Ouh là là ! que de polémiques concernant la surveillance internet pratiquée par les GAFAM. Perso, je m’y suis affranchis en installant des systèmes Gnu/LInux sur toutes mes machines et en utilisant des moteurs de recherches tels que : DuckDuckgo.com ou encore Starpage.com.
Mais je voulais surtout vous dire que grâce à vos commentaires, j’ai pu découvrir le Web3.0, c’est à dire décentralisé.
J’ai découvert ainsi : « AWESOME IPFS » qui propose des navigateurs pré-configurés et un tas d’applications prêtes à l’emploi !
« ScuttleButt » est donc un réseau Web 3.0 peu fréquenté car il n’existe depuis que quelques années, j’ai pu lire que ce réseau décentralisé était l’avenir du web contribuant à retrouver un web vraiment libre.
Donc, nous sommes des « pionniers » qui, un peu comme les premiers hommes sur la lune, faisons nos premiers pas.
A mon tour, je vais continuer à me documenter et voir comment je peux installer mes sites internet consacrés à des tutoriels du genre « How to » ainsi que mes compositions musicales afin qu’ils aient la diffusion qu’ils méritent.
Comme quoi, échanger des points de vues ici, peut devenir vraiment constructif !
Une idée concernant la « June », au lieu de « certifier » d’une manière physique, ce qui ralentis fortement son utilisation courante, pourquoi pas réfléchir à l’utilisation de « SimpleID » ou un autre truc du genre sur la Blockchain ?
Au plaisir de vous lire.
Pour moi la réfutation la plus solide de l’argument « rien à cacher »  , est le fait que ce n’est pas celui qui le dit qui décide ce qu’il doit cacher, pour sa liberté, sa sécurité ou même sa survie. Et ce qu’il doit cacher évolue dans le temps et l’espace. L’homosexualité, était un crime en Angleterre, il y a quelques dizaines d’années et cela l’est encore dans certains pays. Une personne qui voyage le sait et fait attention.
, est le fait que ce n’est pas celui qui le dit qui décide ce qu’il doit cacher, pour sa liberté, sa sécurité ou même sa survie. Et ce qu’il doit cacher évolue dans le temps et l’espace. L’homosexualité, était un crime en Angleterre, il y a quelques dizaines d’années et cela l’est encore dans certains pays. Une personne qui voyage le sait et fait attention.
J’ai fait un séjour en Angleterre quand j’étais jeune, avec un punk affirmé qui n’avait peur de rien (crête iroquois, piercings, tatouages, docs martins, etc). Un prof lui a fortement conseillé de ne pas afficher ses traits de caractère dans la rue, sous peine de passage à tabac. Hé bien, qu’a-t-il fait ? Il a caché tous ses traits de caractère pendant le séjour. Ce n’était pas lui qui décidait ce qu’il devait cacher, mais le lieu et l’époque.
Pour revenir au sujet, Scuttlebutt est un réseau social avec une vision : pseudo anonymat, chiffrement plus fort que des mails chiffrés, et principe de la blockchain pour un historique immuable. C’est un réseau horizontal. Maintenant, la parure est brute, car jeune, mais les fondations techniques sont très solides, et libres. Dans la lignée de ce que nous faisons avec la monnaie libre. Pourquoi des groupes humains travaillent dur à proposer des solutions ? Peut-être parce qu’ils perçoivent des problèmes. Et s’ils les perçoivent, c’est peut-être qu’ils existent… 
Le site : « https://awesome.ipfs.io/ » offre l’accès facilité à la blockchain et a de multiples applications pour accéder facilement à la Web 3.0.
Je vais expérimenter et vous ferai part de mes expériences, si du moins, cette aventure vous intéresse.
A bientôt.
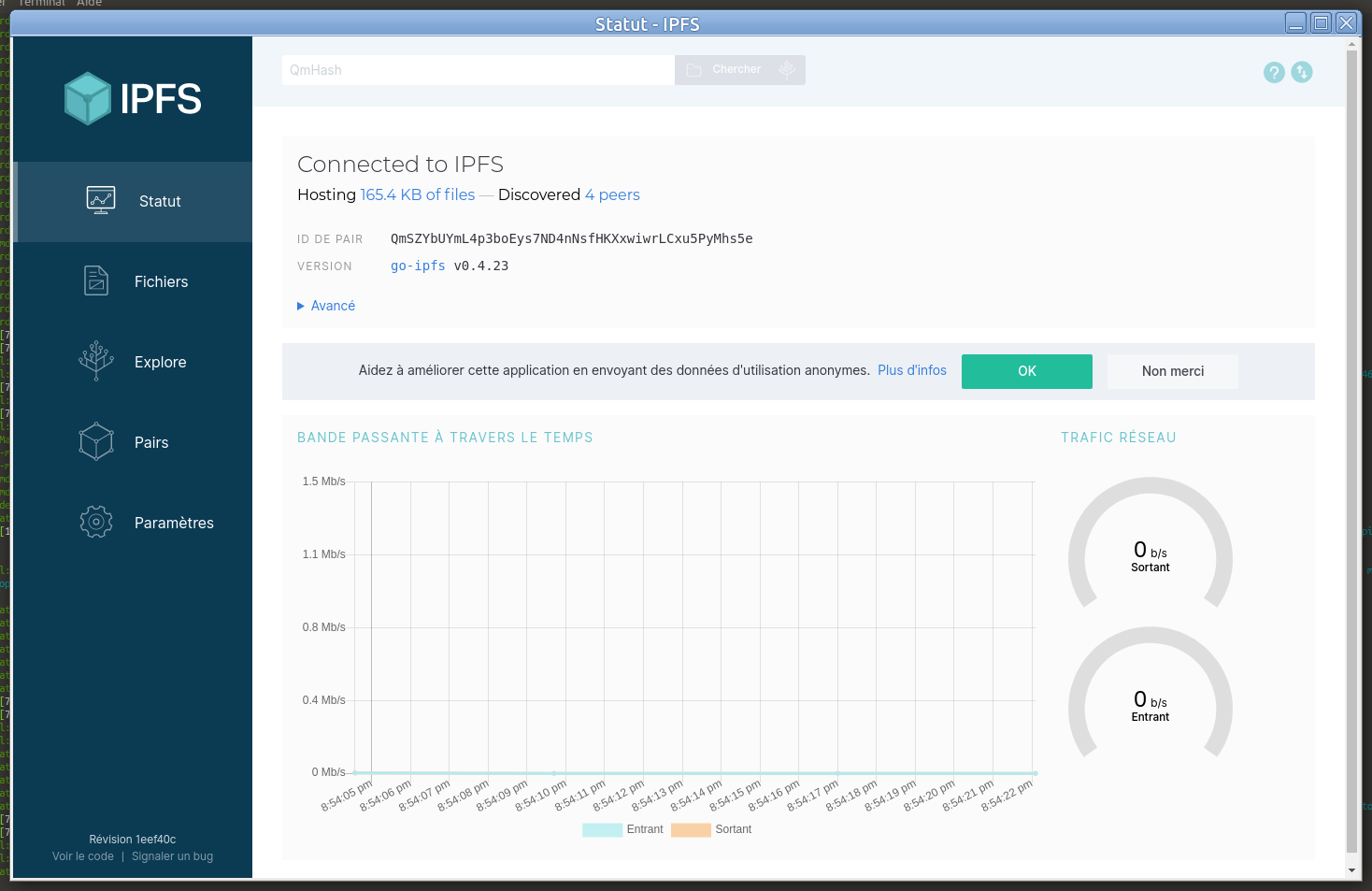
Ça marche bien
Nous ne parlons pas du même type d’environnement de dev.
Il ne s’agit pas de développer un simple logiciel, mais un réseau de stockage distribué autonome!!
Alors pour le tester, il s’agit d’avoir plusieurs « Noeuds » dans différentes conditions de ressources CPU, disque et réseau.
@trezen as-tu bien compris qu’il s’agit de se passer des hébergeurs et des datacenter? L’ensemble des coûts de infrastructure se trouve assumée par chacun, la moitié de la capacité de chaque disque disponible aux communs. Un panneau solaire, 2 ordinateurs et le réseau fonctionne, aussi bien que s’il y en a des millions qui se connectent à leur gré… La data devient un fluide qui se concentre autour de chacun et ses amis.
Pour le moment, le code est mis au point sur un mini réseau de 5 machines (dont 4 en LAN) et qq To.
Contacte moi si tu as des machines à mettre à disposition pour les prochains essais. Plus le réseau sera hétérogène, meilleures seront les simulations…
j’ai trouvé ceci au sujet d’IPFS : ici
J’ai un Pi3 que je tiens à ta dispo pour agrandir l’essaim… (sans jeu de mot)
Super ! je vais pouvoir peut-être héberger mes fichiers musicaux et autres créations !
Bonjour @qoop je t’ai laissé un message privé du coup sur Patchwork.
A bientôt, amicalement, Francis. 
Comment façonner votre essaim ipfs en fonction des connexions de vos amis Scuttlebutt ? Et pourquoi.
How to shape your ipfs swarm as your SSB friends connexions ? And why.
https://viewer.scuttlebot.io/%mQNrL80QUreDQnzvBZPZa9t4bGcNPBi8VTC0xCXQl54=.sha256
ZEN=1000(10/10)
#zenbot,astroport
Do you want to read Glue CODE  ?
?
![]()
Une fois que le compte Cesium+ associé à son compte « SSB » est geolocalisé, la A.Station collecte les annonces gchange qui lui sont proche et publie la liste sur notre journal ![]()
Les petites annonces du matin
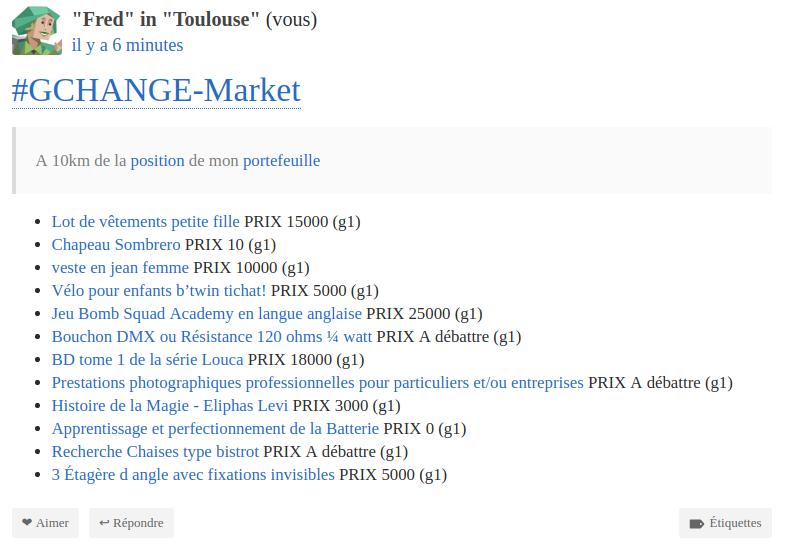
Voir le script en dev: astroport/gchange_MONITOR.sh at master - astroport - P2Git
A bientôt dans Astroport!
Personne n’est absolument Ange ou Démon, mais chacun peut le paraître dans l’espace de conscience relative de l’autre. J’ai été surpris de voir que la solution était similaire au paramètre par défaut de SSB

Oui j ai compris.
Il y a tout de même un limite à scuttelbut.
Recement j ai perdu TOUTES mes données, pas eu moyen de les reccuperer.
Et donc mon compte scuttelbut, et tout ce que j y avais déjà posté est perdus, irrémédiablement.
Que dire si cela avais été mon portefeuille principale…
Startpage, duckduck : Je ne vois pas en quoi ces deux moteurs t’affranchissent des gafam.
Je les ai perdu aussi. J’ai remis ma clé secrète, et j’ai retrouvé une bonne partie de mes messages petit à petit en me re-liant à mes amis…
duckduck (comme invidio) va servir de ‹ tampon › entre toi et google (par exemple). Du coup, quand tu vas faire ta recherche, au lieu d’aspirer tes données, gogol va aspirer celles du serveur duckduck, c’est à dire rien d’exploitable. De plus, ça rend chaque recherche « premium », ça ne « présélectionne » pas les données comme d’hab en fonction de tes anciennes recherches… C’est pas mal.
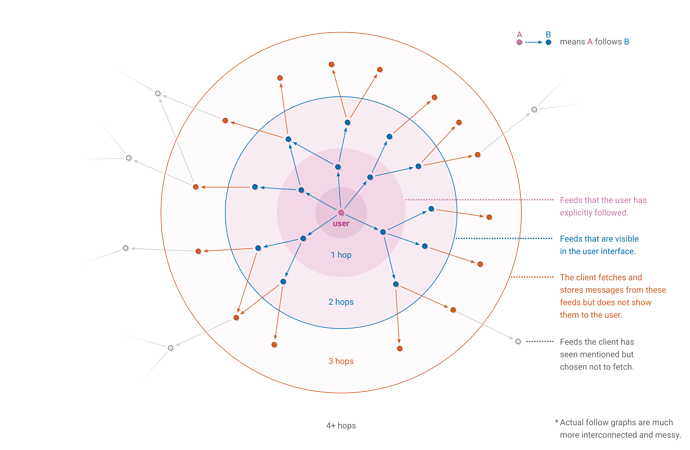
Voici un modèle visuel du comportement d’un réseau ScuttleButt
")

Un système de confiance et de modération pour le Web décentralisé
Les réseaux sociaux publics, les sections de commentaires et les forums de discussion sont brisés. L’internet promettait un accès illimité à la connaissance et des conversations réfléchies et intelligentes avec des personnes du monde entier. Au lieu de cela, nous avons les trolls, les manipulateurs, l’indignation et le spam.
On pourrait penser que la décentralisation aggraverait ces problèmes. Après tout, la plupart des réseaux sociaux décentralisés ou non modérés se transforment au fil du temps en feux de poubelle de contenu de faible qualité. Sans modérateurs ni menace d’interdiction, les pires utilisateurs se sentent encouragés à répandre leurs bêtises sur l’ensemble du réseau. Au fur et à mesure que la qualité se dégrade, les meilleurs utilisateurs sont éteints et le réseau devient moins utile et moins engageant.
Mais il existe une solution qui redonne du pouvoir au peuple, en lui permettant de modérer son propre monde, en travaillant avec ses amis pour le garder libre de tout discours mesquin. Il fonctionne en reflétant le monde réel : donner à chacun une réputation et la possibilité d’ignorer ceux qui ont une mauvaise réputation.
Dans cet article, je vais montrer comment un système de modération décentralisé peut non seulement être aussi bon que les systèmes existants, mais aussi les surpasser, en créant un réseau social de meilleure qualité.
Mais d’abord, prenons un peu de recul et voyons ce que la modération centralisée peut faire de mal.
La modération centralisée et ses défauts
La modération centralisée fait référence aux réseaux sociaux ou aux forums où une entité centrale, telle qu’une société ou le propriétaire du site, a la seule autorité de modération sur le contenu. Il existe généralement un ensemble de règles que tous les utilisateurs doivent suivre et, si l’utilisateur est contourné, son contenu est supprimé et les récidivistes sont interdits.
Les défauts concernent le contenu que certains utilisateurs apprécient et d’autres non, et la façon dont vous traitez ce contenu.
Avec la modération centralisée, nous devons tous respecter les mêmes règles, de sorte que les sites doivent faire leur travail du mieux possible. S’ils sont trop sévères dans la modération, ils auront un bon rapport signal/bruit, mais le contenu peut devenir trop partisan ou ennuyeux. S’ils sont trop indulgents, le contenu deviendra plus bruyant, ce qui le rendra moins agréable, car il y aura alors plus de messages à trier sans effort. Et certains des pires contenus vont rebuter de nombreuses personnes.
Spectres de contenu
Imaginez que vous évaluiez chaque élément de contenu des médias sociaux en fonction d’un spectre de contenu parmi les suivants :
Basse qualité → Haute qualité
Infraction faible →Haute Infraction
Précise → Imprécise
Examinez où le contenu que vous aimez le plus se situe sur ces spectres. Ce n’est probablement pas un point fixe, mais plutôt une fourchette de ce qui est considéré comme acceptable et une plus petite fourchette de ce qui est considéré comme idéal.
Le pire contenu se situe généralement à l’extrémité de ces spectres. Le spam est de très mauvaise qualité, les détracteurs sont très offensants et les manipulateurs sont souvent inexacts.
Ainsi, un site a un bon rapport signal/bruit lorsqu’un bon pourcentage de son contenu tombe dans sa zone idéale.
Les utilisateurs veulent voir un contenu qui correspond à leur zone idéale, plutôt que de devoir entendre l’opinion de chacun. Si trop de choses tombent en dehors de leur zone idéale, ils s’ennuient souvent et quittent le site.
Parfois, une modération importante des contenus qui sortent de la « zone idéale » est une bonne chose, car cela signifie que vous apprécierez davantage les contenus que vous lisez, sans avoir à vous frayer un chemin à travers des contenus purement acceptables.
Le principal défaut des réseaux centralisés est qu’en disposant d’un ensemble de règles que tous les utilisateurs doivent respecter, les sites prédéfinissent les spectres de contenu autorisés. Ce spectre de contenu détermine non seulement le type d’utilisateurs qui seront autorisés sur le site, mais aussi ceux qui seront attirés par le site, car les utilisateurs dont le spectre de contenu correspond le plus au site auront tendance à rester plus longtemps sur le site.
Il s’avère que les services centralisés ont réfléchi à ce problème au cours de la dernière décennie et ont trouvé une solution : des flux déterminés par des algorithmes. Si chacun a son propre flux, un algorithme d’IA peut apprendre quel est le spectre de contenu idéal et montrer le contenu qui lui plaît le plus. Ce flux est un filtre sur le monde qui permet de voir le site sous un jour « idéal ».
Les flux déterminés de manière algorithmique sont la prochaine étape dans l’évolution des réseaux sociaux, mais ces flux ont leur propre série de problèmes.
Le problème de l’alimentation choisie de façon algorithmique
Avoir un flux social piloté par un algorithme peut être utile pour faire apparaître tous les contenus que vous aimeriez le plus voir sur un réseau social, mais il a aussi des côtés sombres auxquels on pense le plus rarement.
Le plus gros problème de l’utilisation d’algorithmes pour personnaliser les flux sociaux est que l’utilisateur n’a aucune idée des décisions prises par l’algorithme. Avec l’essor des réseaux de neurones, il arrive que même les développeurs de ces algorithmes soient incapables d’expliquer leur logique interne.
Lorsqu’un message est publié, même s’il a nécessité beaucoup de temps et d’efforts, l’algorithme peut décider qu’il est de mauvaise qualité, le classer au bas de l’échelle et faire en sorte qu’il n’apparaisse jamais dans les flux choisis par l’algorithme de ses amis. Dans ce paradigme, ni l’opinion d’un utilisateur ni celle de ses amis ne comptent, l’algorithme a décidé et sa décision est définitive.
En outre, comme ces algorithmes sont appliqués à des millions, voire des milliards de personnes, les entreprises ou organisations manipulatrices ont une forte incitation financière à les rétroconcevoir. Si elles parviennent à comprendre le fonctionnement de ces algorithmes, les entreprises peuvent les adapter pour donner la priorité à leur propre contenu afin d’atteindre le sommet du plus grand nombre de flux possible. Cette situation s’aggrave si les incitations financières du réseau social sont alignées sur celles de l’entreprise. Même si le réseau de médias sociaux lui-même est tout à fait bienveillant, ce sera toujours un problème.
Un dernier défaut de ces algorithmes est l’incitation des réseaux sociaux à vous tenir au courant de leur produit. Cela signifie que les algorithmes sont optimisés pour afficher le contenu que vous aimez et cacher le contenu que vous n’aimez pas. Bien qu’utile avec modération, cette pratique peut rapidement devenir dangereuse si elle est optimisée pour les coups de dopamine et l’attrait émotionnel à court terme sur la santé mentale et le bien-être.
Qui a choisi les modérateurs ?
La modération centralisée est une question fondamentale, rarement débattue : L’idée qu’une tierce partie est nécessaire pour modérer le contenu des utilisateurs.
Pourquoi ne pouvons-nous pas en décider par nous-mêmes ? Pourquoi devons-nous être soumis aux caprices de modérateurs clandestins et d’algorithmes opaques qui décident qui est autorisé et quel contenu est acceptable ?
Les mondes décentralisés n’ont pas besoin d’être structurés de cette manière. Les réseaux décentralisés ont le potentiel de réaliser l’intention originale de l’internet : des mondes ouverts à tous sans règles mondiales, dans lesquels chacun peut participer et modérer son propre domaine. Les utilisateurs choisissent à qui faire confiance, qui ignorer et comment leur alimentation est commandée.
La solution : Un système de modération décentralisé qui s’adresse à tous
Pour avoir la meilleure expérience sociale possible, la modération doit être personnalisée. Les individus doivent pouvoir décider qui peut faire partie de leur monde et qui ne le peut pas. Il n’est pas possible pour une entreprise de faire des politiques que des millions de personnes approuvent et qui n’ont pas d’inconvénients et de conséquences involontaires.
Cela ne signifie pas que les modérateurs mondiaux ne sont plus nécessaires. Ils sont toujours incroyablement utiles, mais ne sont plus obligatoires. Les modérateurs devraient plutôt être « opt-in », laissant à un individu, ou à un groupe d’individus, le choix du modérateur pour son « monde ». Les utilisateurs peuvent ainsi bénéficier des services de sociétés spécialisées dans la détection et l’élimination du spam, ou des réseaux de robots ou de l’Astroturfing, sans être obligés de les utiliser.
Comment cela fonctionne-t-il ?
Dans la vie réelle, la confiance vient des amis et de la famille, c’est-à-dire des personnes en qui une personne a déjà confiance pour l’aider à déterminer qui peut et ne peut pas avoir confiance. Lorsqu’un ami commence à s’associer à des personnes mal intentionnées, soit on essaie de les éloigner, soit on perd confiance en elles.
C’est exactement comme cela que fonctionne le nouveau système de confiance décentralisé. Un utilisateur évalue la fiabilité de certaines des personnes rencontrées en ligne, puis la confiance de tous les autres est calculée sur la base de ces évaluations. Dans cette mise en œuvre, les cotes de confiance doivent être publiques, afin que chacun puisse calculer la confiance des amis des amis. À l’avenir, un système de confiance plus privé pourrait être développé dans le même sens.
La deuxième partie est un filtre qu’un utilisateur peut appliquer à son flux social pour cacher tous ceux dont la cote de confiance est inférieure à un seuil particulier.
Il ne s’agit pas d’un cahier des charges définitif, mais d’une ébauche de la manière dont ce système peut fonctionner. Cet essai explique pourquoi nous devrions construire ce système et comment il pourrait fonctionner, plus que les détails exacts de sa mise en œuvre.
Pour démarrer le système, l’utilisateur doit d’abord donner une note aux personnes en qui il a confiance ou dont il se méfie sur le réseau. Il peut s’agir de personnes connues dans la vie réelle ou non. Les notes peuvent se situer entre -100 et 100. Cette note doit correspondre au degré de confiance d’un utilisateur dans la publication d’un contenu similaire à son spectre de contenu idéal, car cette note façonnera le contenu vu sur le réseau social.
Lorsqu’un utilisateur rencontre de nouvelles personnes en ligne, il peut leur donner +/- 1 voix en fonction des différents contenus publiés. Pour les spammeurs ou les trolls évidents, on pourrait immédiatement leur donner une note négative.
Ainsi, alors que des éléments de contenu individuels peuvent être évalués, la cote de confiance est attribuée à une personne. En effet, la plupart des gens publient des contenus dans un spectre de contenu similaire. Cependant, il est important que la confiance soit également liée au contenu, de sorte que lorsqu’un utilisateur pose la question « Pourquoi mon ami se méfie-t-il de ce type ? », il puisse voir le contenu exact qui a suscité la méfiance.
Après avoir donné quelques notes de confiance, l’algorithme va calculer la fiabilité des amis des amis (à deux degrés de distance) et même de leurs amis (à trois degrés). Pour ce faire, il prend toutes les personnes en qui un utilisateur a confiance et toutes les personnes en qui il a confiance, puis multiplie les niveaux de confiance pour obtenir une évaluation personnelle de la confiance de chacun. Même si un utilisateur n’évalue que dix personnes, ces dix personnes en évaluent dix autres et ces dernières en évaluent dix autres, l’utilisateur aura des évaluations de confiance pour plus de 1000 personnes sur le réseau.
Lorsqu’une cote de confiance est attribuée, elle est fixe et n’est pas affectée par les cotes des autres.
Les personnes dont un utilisateur se méfie n’ont aucun effet sur leur cote de confiance envers les autres. C’est comme dans la vie réelle, où lorsque quelqu’un rencontre quelqu’un qu’il n’aime pas, il ne se soucie pas de savoir qui sont ses amis ou ses ennemis. Elle empêche également les utilisateurs malveillants de jouer sur le système.
Désormais, au lieu de devoir bloquer individuellement les spammeurs, les trolls et les haineux de votre monde, dès qu’un ami de confiance évalue mal quelqu’un, il se cache automatiquement, ce qui facilite grandement la modération des trolls ou spammeurs évidents.
L’algorithme
L’algorithme général est le suivant : la cote de confiance de toute personne qui n’a pas encore de cote fixe est la racine carrée du degré de confiance d’un utilisateur envers un ami commun multiplié par le degré de confiance de l’ami commun envers l’étranger. Dans le cas des négatifs, le négatif est ignoré lors du calcul de la racine carrée (il n’y a donc pas de nombres imaginaires). Lorsqu’un utilisateur a plusieurs amis communs, leurs scores sont additionnés avant la racine carrée et ce nombre est divisé par le nombre total d’évaluateurs (de sorte que quelqu’un qui est populaire n’est pas naturellement plus fiable).
Il y a une petite faille dans cet algorithme. Si un utilisateur a un ami Alice qui est noté à 10, et qu’il a ensuite un meilleur ami Bob qui est noté à 100, le score pour Bob sera (10)(100)= 31,6.
C’est bizarre parce que l’utilisateur ne fait pas autant confiance à Alice, alors pourquoi ferait-il plus confiance à Bob qu’à elle ? Comme dans la vie réelle, si une connaissance amène un ami à une fête, peu importe à quel point il dit l’aimer, on ne lui fera pas plus confiance qu’à cette connaissance.
Voici une présentation de ce système en action, avec des utilisateurs générés au hasard qui font confiance à d’autres utilisateurs sont des niveaux aléatoires :
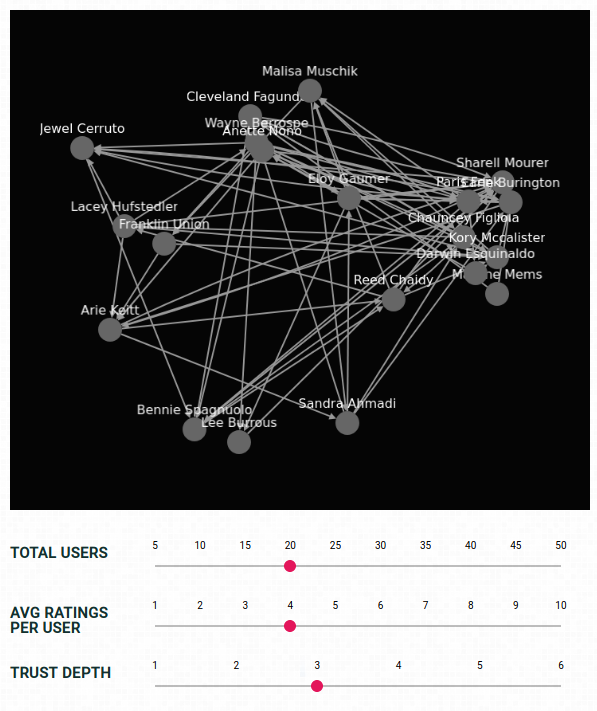
Vous pouvez ajuster le nombre total d’utilisateurs et les notes moyennes par utilisateur pour voir comment le système fonctionne à mesure que de plus en plus de personnes le rejoignent et l’utilisent. Vous pouvez également ajuster la profondeur, ou les degrés de séparation, pour laquelle les cotes de confiance sont calculées.
Les flèches représentent le degré de confiance de chaque utilisateur envers l’utilisateur vers lequel la flèche pointe. La couleur de chaque utilisateur représente le degré de confiance de l’utilisateur sélectionné (le bleu), calculé par l’algorithme décrit dans ce post. Le vert vif représente une confiance de 100 et le rouge vif une confiance de -100, avec un gradient pour les scores intermédiaires.
Le code source de cette démo est open source sur Github. J’ai mis en place une version simple de l’algorithme de confiance en JavaScript que vous pouvez utiliser pour votre propre réseau social si vous le souhaitez et qui est déjà assez rapide pour la plupart des cas d’utilisation.
Mise en œuvre technique
Cela peut être mis en œuvre avec Scuttlebutt, ou de tout autre réseau social à source ouverte. Avec Scuttlebutt, la seule exigence est un plugin de confiance qui permet aux utilisateurs de poster des messages de confiance qui contiennent un identifiant d’utilisateur/feed et leur évaluation de cet utilisateur. Grâce à ces informations, l’algorithme peut calculer la cote de confiance de tous les utilisateurs en fonction des messages de confiance que chacun a postés.
En ce qui concerne l’expérience de l’utilisateur, ce plugin pourrait ajouter des boutons de vote positif/négatif à chaque élément de contenu qui augmente ou diminue la confiance dans l’utilisateur qui a publié ce contenu. Le filtre de confiance peut être une simple liste déroulante en haut à droite du fil qui, lorsqu’un niveau de confiance est choisi, tous les messages des utilisateurs ayant une cote de confiance inférieure à ce niveau seront cachés.
En termes de performances, la démo ci-dessus utilise un algorithme simple en JavaScript, et même celui-ci est capable de recalculer la confiance de plus de 100 000 personnes en quelques millisecondes seulement. Vous pouvez voir le benchmark ici.
Cela peut s’étendre à des centaines de millions d’utilisateurs car chaque utilisateur n’a besoin de calculer que les évaluations de quelques centaines à des dizaines de milliers de personnes. Comme il s’agit d’un logiciel libre, cet algorithme peut être mis à jour et amélioré au fil du temps si de meilleurs moyens de calculer la confiance sont découverts. Un exemple de texte écrit de cet algorithme se trouve à l’annexe A.
Avantages supplémentaires de la confiance décentralisée
Choisissez vos propres modérateurs
Il est toujours bon que les grandes organisations deviennent des modérateurs, car elles ont plus de ressources et de poids que les individus. La différence est que, dans un monde décentralisé, on peut choisir ses propres modérateurs. Imaginez un avenir où le New York Times aurait son propre utilisateur « Trust Beacon » sur la plate-forme. Chaque fois qu’ils signalent une fausse nouvelle ou un faux contenu, cette balise de confiance peut marquer le contenu et ceux qui l’affichent ou le créent à une confiance de -10 % par exemple.
Si un utilisateur fait confiance au New York Times, il peut lui attribuer une note de confiance de 50, par exemple, et il appliquera automatiquement ses notes de confiance à son flux social. C’est la même chose que de faire confiance à n’importe quel autre utilisateur.
Ces balises de confiance pourraient être mises en place par n’importe quelle société de médias, par de faux sites web de collecte d’informations, ou même par des sociétés comme NetNanny qui veulent filtrer les contenus dangereux pour les enfants. Les gens peuvent faire confiance à qui ils veulent et ces notes de confiance seront ensuite appliquées à leur alimentation. De cette façon, un grand réseau d’amis n’est pas nécessaire pour aider à filtrer le contenu, ces entreprises peuvent le faire si elles le souhaitent.
La confiance peut être liée à des messages ou des images
Ce système de confiance ne doit pas nécessairement s’appliquer uniquement aux utilisateurs. Il peut s’appliquer à des postes individuels ou à des éléments de contenu. Par exemple, sur Scuttlebutt, chaque média est stocké sous forme de blob, où le nom du fichier est un hachage de son contenu. Ce hachage est essentiellement une empreinte d’image, de vidéo, de chanson, etc. sur le réseau.
Une balise de confiance telle que Snopes qui débloque les fausses informations peut avoir un compte qui signale les images qui sont fausses. Comme cette image peut être identifiée sur le réseau par son hachage, si un utilisateur souscrit à la balise de confiance Snopes, il peut automatiquement signaler et filtrer ce contenu pour lui, même si cette image a été réaffichée 100 fois avant qu’il ne la voie.
Cela pourrait également se faire avec des contenus pornographiques ou violents qui ne sont pas sûrs pour les enfants. Des services tels que NetNanny pourraient maintenir une liste de ces images et vidéos réservées aux adultes et les bloquer automatiquement pour les enfants, créant ainsi un espace plus sûr à explorer que même les grands réseaux peuvent gérer.
Vous choisissez ce que la confiance signifie pour vous
Ce qui est intéressant dans ce système, c’est qu’un utilisateur n’est pas obligé de faire confiance à des gens sur la base de la vérité. La confiance est un nombre arbitraire qui peut être utilisé pour représenter tout ce que l’on voudrait voir plus dans votre monde social. Si un utilisateur souhaite que les évaluations de confiance soient basées sur des croyances partagées, sur la positivité ou même sur la proximité géographique, c’est à lui de décider.
Imaginez un monde où, au lieu que chacun ait un profil social, ils ont un profil pour chaque sujet qui les intéresse. On pourrait avoir un profil pour la programmation, pour la politique, pour les jeux, pour la décentralisation, etc. Si cela devient courant, la confiance que l’on accorde à quelqu’un peut être directement liée à son domaine de compétence. Souvent, la confiance n’est pas dans la personne, mais dans le fait qu’elle sache de quoi elle parle à ce moment-là.
Elle pourrait aussi être mise en œuvre de manière à ce que les gens aient plusieurs cotes de confiance, chacune étant marquée par un sujet. Cependant, cela ajouterait beaucoup plus de complexité, notamment en ce qui concerne l’identification du sujet auquel chaque message appartient.
Recréer des petites communautés
La plupart du temps, les amis sont choisis par hasard. Il a été démontré que le secret de l’épanouissement d’une amitié réside dans les multiples rencontres aléatoires. L’une des raisons pour lesquelles les gens se font rarement des amis via les grands réseaux sociaux (Twitter, Facebook, Reddit, etc.) est qu’ils sont si vastes et si dispersés que les gens rencontrent rarement deux fois la même personne s’ils ne sont pas déjà amis.
Imaginez si votre flux social montrait tous ceux que vous suivez, ainsi que tous ceux qu’ils suivent, avec leur rang basé sur la cote de confiance. Vous pourriez découvrir de bons amis d’amis que vous n’avez jamais rencontrés en publiant un contenu que vous aimez vraiment. Au fil du temps, vous pourriez commenter leurs messages, contribuer à la conversation et, éventuellement, nouer une relation.
Le système de confiance permettrait aux meilleurs amis des amis d’apparaître dans le flux des utilisateurs plus souvent qu’un oncle fou au hasard, des messages de groupes ou même des connaissances à peine connues. Cela pourrait conduire à de nouvelles connexions et à de nombreuses nouvelles amitiés étonnantes avec des personnes qui étaient auparavant juste hors de contact. Plus il y aura d’intérêts et de personnes en commun, plus les utilisateurs se verront en ligne et plus ils auront de chances de se connecter.
C’est la modération à l’échelle de l’internet
L’avenir sera rempli d’IA et de robots qui créent des centaines de milliers de comptes afin de prendre le contrôle des réseaux sociaux. Avec la confiance décentralisée, il suffit d’un ami ou d’une balise de confiance pour remarquer ces robots et se méfier d’eux. Il doit être possible de faire passer la modération à un niveau tel qu’elle puisse combattre des milliers, voire des millions, de faux utilisateurs et de faux robots. Elle ne peut pas s’étendre en ayant des modérateurs désignés, elle ne peut s’étendre que si tout le monde participe à la modération dans une partie du monde.
Les inconvénients de la confiance décentralisée
Ce système présente maintenant des inconvénients potentiels. Comme pour toute chose, lorsqu’on donne la liberté aux gens, certains vont l’utiliser à mauvais escient. Ce n’est pas grave. Il ne faut pas dire aux gens ce qu’ils doivent faire de toute façon.
La première question évidente est la création de chambres d’écho ou de cultes en ligne, où au lieu de choisir la vérité et de rechercher les meilleures informations, les gens font confiance à ceux qui confirment leurs croyances existantes.
Cette situation peut être quelque peu atténuée par la possibilité de fixer un niveau de filtre de confiance à un niveau bas, même dans les négatifs, pour voir des postes et des opinions auxquels on n’est pas habituellement exposé. Il appartient à l’utilisateur final de décider s’il souhaite ou non s’exposer à des opinions divergentes.
Il appartient aux individus de déterminer ce qui leur convient le mieux. Bien sûr, on pourrait espérer qu’ils fassent de bons choix, mais ce n’est pas le rôle de la société de sauver les gens d’eux-mêmes. Il est bien préférable d’avoir cette liberté et le pouvoir de l’utiliser ou d’en abuser, que de permettre aux entreprises de construire la chambre d’écho à huis clos.
Conclusion
La mise en œuvre sera à code source ouvert et ouverte à tous. La mise en œuvre a déjà commencé, mais il reste encore beaucoup de travail à faire. Si quelqu’un a entendu parler de quelqu’un qui construirait quelque chose de semblable, il serait merveilleux de se rencontrer pour que cette idée puisse se concrétiser.
C’est passionnant de penser aux possibilités que ce système apporterait. Il est possible de créer des fils de conversation plus stimulants sans que les trolls ne tentent de gâcher le plaisir. Dans l’état actuel de l’internet social, c’est difficile, mais cela vaut la peine d’être fait.
Annexe A : Exemple de système de confiance
Voyons un exemple, en commençant par Tom.
- Tom a une meilleure amie, Alice, à qui il fait confiance à 100
- Tom a également un ami, Mike, en qui il a confiance à 50
- Alice connaît un type, Dave, qui est un menteur compulsif et lui fait confiance à -20
- Alice a un collègue de travail, Jeremy, qui est un type bien, mais elle ne le connaît pas bien, alors elle fait confiance à 10.
- Alice a une collègue de travail, Sophie, qui partage constamment de fausses indignations, mais qui est par ailleurs une bonne personne, à qui elle fait confiance à -5.
- Mike est le meilleur ami de Jeremy et lui fait confiance 40
- Mike connaît Sophie et l’aime bien, et lui fait confiance 15
- Dave a un meilleur ami, Barry, à qui il fait confiance à 100
- Sophie a une meilleure amie, Emily, à qui elle fait confiance à 100
Alors que Tom n’a évalué que 3 personnes, le logiciel va maintenant calculer ses évaluations de confiance personnalisées pour les 7 personnes présentes ici :
Il y a d’abord les amis immédiats. Si vous avez noté quelqu’un qui est la note fixe pour eux, cela n’est pas influencé par quelqu’un d’autre :
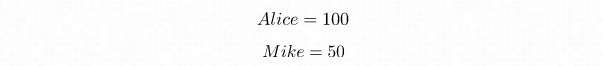
Puis les amis secondaires :

Puis les amis du tertiaire :
Barry n’est pas noté comme Tom.Dave < 0

Il y a quelques choses intéressantes qui se passent ici. Tout d’abord, Sophie se retrouve avec une note de confiance légèrement positive, malgré le fait qu’Alice, la meilleure amie de Tom, affirme qu’elle partage trop de fausses indignations. C’est parce que Mike lui fait encore confiance. Si Tom remarque qu’elle partage beaucoup de fausses informations, il peut soit l’évaluer lui-même, ce qui signifie que les évaluations de ses amis ne s’appliqueront plus, soit évaluer Mike à un niveau inférieur car il devient évident que Mike ne se soucie pas autant de la vérité.
Nous constatons également que la note de Barry n’est pas du tout calculée (elle serait donc de 0 par défaut). En effet, si nous ne faisons pas confiance à une personne, nous ne faisons pas non plus confiance à ce qu’elle dit sur la réputation des autres, de sorte que le système ne peut pas être manipulé par des acteurs malveillants. De même, si Tom attribuait à Sophie une note négative, la note d’Émilie ne s’appliquerait plus et Émilie aurait la note par défaut de 0.
Enfin, la note d’Emily est plafonnée à la même note que celle de Tom.Sophie, car on ne note jamais les amis des amis plus haut que l’ami commun.
Toutes les personnes ci-dessus sont maintenant dans une grande discussion sur la politique et Tom peut voir cette discussion se produire dans son flux. Comme Tom veut être bien informé sans que des menteurs soient impliqués, il fixe son niveau de filtre de confiance à 10, de sorte que toute personne ayant une note inférieure à 10 sera cachée. Cela permet à Tom de filtrer son monde sans investir beaucoup d’efforts dans le processus. Dans ce flux, il ne voyait que les messages d’Alice, Mike, Jeremy et Emily. Les messages de Sophie, Dave ou Barry seraient cachés.
Source
https://adecentralizedworld.com/2020/06/a-trust-and-moderation-system-for-the-decentralized-web/
@qoop, je ne suis pas modo, mais ce message me semble carrément hors-sujet sur ce forum. Pourquoi pas le publier et mettre l’article en lien.